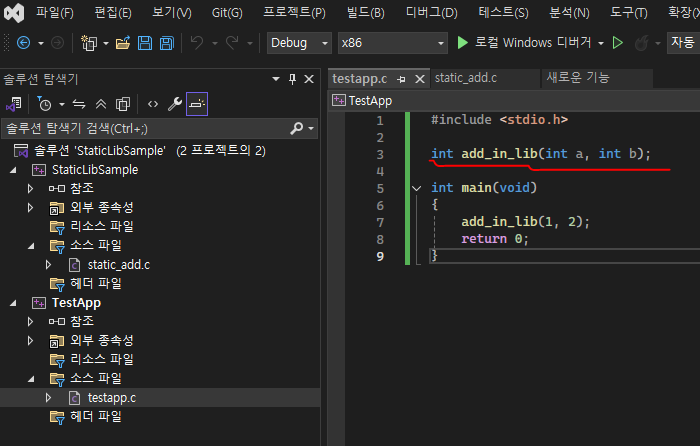
스택 프레임은 함수 호출과 반환 과정에서 사용되는 데이터 구조로, 주로 함수 호출 시 함수의 지역 변수, 반환 주소, 매개변수 등을 저장하는 데 사용된다. 스택 프레임은 프로그램이 실행될 때마다 생성되고, 함수가 반환될 때마다 소멸된다.
📌 스택 프레임 지정원리 #1
스택 메모리 주소는 0번지를 향해 증가한다.
지역변수는 선언한 순서대로 스택에 Push 한다.
매개변수는 오른쪽부터 스택에 Push 한다.
스코프 단위로 끊어서 표시한다. ( 함수는 별도 단락으로 표시한다. )
📌 스택 프레임 지정 ( 지역변수 )
예제를 통해 살펴보자
#include<stdio.h>
int main(void)
{ // 1번째 스코프
int a = 3; // 1번째 a
int b = 4;
int aData[5] = { 0x10, 0x20, 0x30, 0x40, 0x50 };
printf("a: %d\n", a); // 1번째 a가 출력
if(a > 2) // 1번째 a를 확인
{ // 2번째 스코프
int a = 5; // 2번째 a
printf("a: %d\n", a); // 2번째 a가 출력
}
return 0;
}
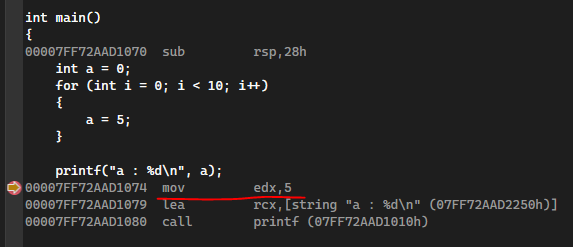
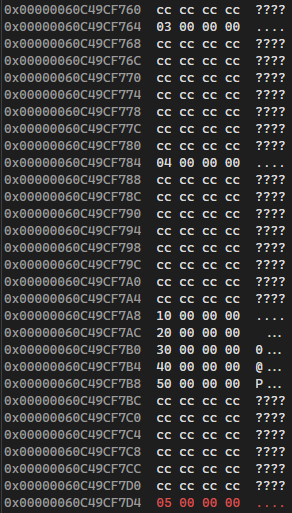
위 코드를 실행할때 스택 영역에 쌓이는 데이터를 그림으로 살펴보면 다음과 같다.
Stack 영역 구조
첫번째 a와 2번째 a는 이름은 같지만 메모리에 적재되는 위치가 다르기 때문에 다른 지역 변수라고 생각할 수 있다.
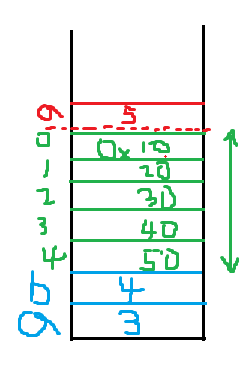
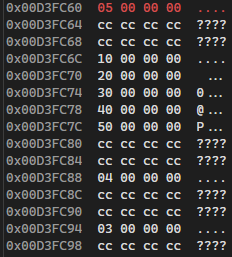
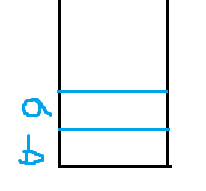
실제 메모리에 어떻게 들어가는지 확인해보자.
32비트 환경 Stack 영역
그림으로 표시한 Stack 영역처럼 메모리에도 순서대로 데이터가 쌓이는 것을 확인할 수 있다.
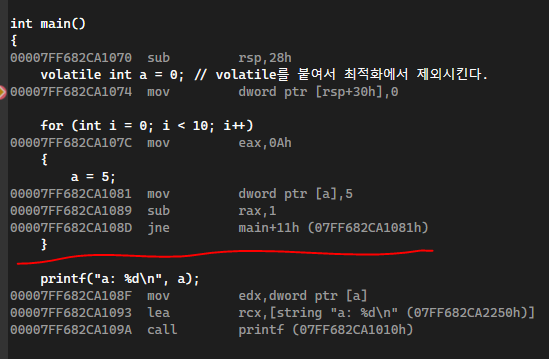
위 구조는 32비트 환경에서 빌드한 것인데, 64비트 환경에서 빌드하면 전혀 다른 스택 프레임이 나타난다.
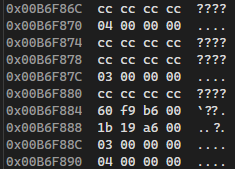
64비트 환경 Stack 영역
64비트 환경에서는 Stack이 아래로 쌓이는 것을 확인할 수 있다.
64비트에서는 Stack 영역을 최대값까지 증가된 채로 지정해 놓고 위에서 아래로 내려오는 방식으로 관리하는 것
📌 스택 프레임 지정 ( 함수 )
예제를 통해 살펴보자
int add(int a, int b);
위와 같은 함수가 있을때 호출하면 스택 프레임에 매개변수가 쌓이는 순서는 아래 그림과 같다.
앞서 언급한것 처럼 매개변수는 오른쪽부터 아래에 순서대로 쌓인다.
#include <stdio.h>
int add(int paramA, int paramB)
{
int a = paramA;
int b = paramB;
printf("a: %d b: %d", a, b);
}
int main()
{
add(3, 4);
return 0;
}
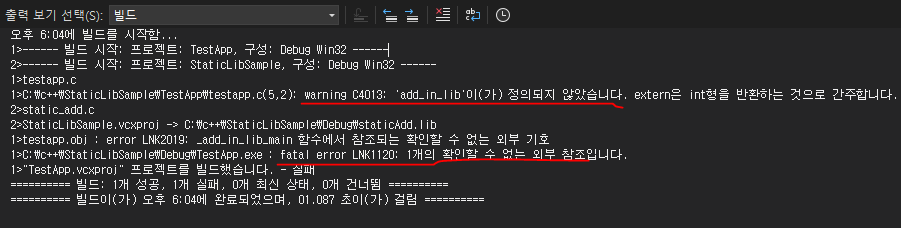
위 코드를 실행할때 함수안에 지역변수가 있으면 매개변수가 먼저 쌓일까? 지역변수가 먼저 쌓일까?
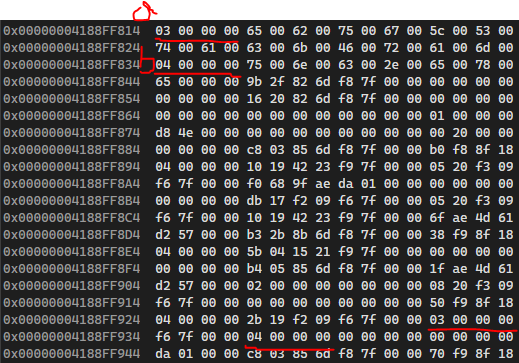
32비트 환경에서 메모리를 살펴보자.
메모리를 살펴보면 위 그림과 같다. 매개변수가 먼저 쌓이고, 이후 지역변수가 쌓이는 것을 확인할 수 있다.
#include<stdio.h>
void swap(int *pA, int *pB)
{
int nTmp = *pA;
*pA = *pB;
*pB = nTmp;
return;
}
int main(void)
{
int x = 3, y = 4;
swap(&x, &y);
printf("%d, %d\n", x, y);
return 0;
}
📌 참조에 의한 전달
#include<iostream>
using namespace std;
void swap(int& pA, int& pB)
{
int temp = pA;
pA = pB;
pB = temp;
return;
}
int main(void)
{
int a = 10;
int b = 20;
swap(a, b);
cout << "a = " << a << ", b = " << b << endl;
return 0;
}
주소에 의한 전달은 c로 작성했고, 참조에 의한 전달은 c++로 작성했다.
실제 어셈블리로 매개변수가 전달되는 부분을 확인하면 어떤 모습일까?
c 주소에 의한 매개변수 전달
c++ 참조에 의한 매개변수 전달
어셈블리 수준에서 두 코드를 보면 똑같이 ptr 즉, 주소로 접근해서 데이터를 처리하는 것을 확인할 수 있다.
이처럼 주소에 의한 전달과 참조에 의한 전달은 모두 주소를 이용해서 데이터를 처리하는 것이므로 차이가 없다.
어떤 의미에서는 포인터가 c++ 이나 JAVA에서 참조자가 되어주는 것이라고도 볼 수 있겠다.
매개변수를 전달하는 방식은 여러 가지가 있고, 각 기법은 함수 호출 시의 동작 방식과 메모리 사용에 따라 다르다.
값에 의한 전달
주소에 의한 전달
참조에 의한 전달
📌 값에 의한 전달( Call by Value )
값에 의한 전달은 가장 기본적인 매개변수 전달 기법이다. 함수 호출 시 매개변수에 전달된 값이 복사되어 함수의 지역 변수에 저장( Stack에서 관리 )된다.
함수 호출 시, 매개변수의 값이 복사되어 함수에 전달
함수 내부에서 해당 값을 수정해도 호출한 함수의 값은 변경되지 않는다.
예시
#include <stdio.h>
void Test(int x) {
x = 20; // 함수 내부에서만 x의 값이 변경됨
}
int main() {
int a = 10;
Test(a); // a의 값을 Test에 전달, 값이 복사됨
printf("%d\n", a); // 출력: 10
return 0;
}
📌 주소에 의한 전달( Call by Reference )
주소에 의한 전달은 함수 호출 시 매개변수의 주소를 전달하는 방식이다.
함수 호출 시, 매개변수의 주소가 전달된다.
함수 내부에서 해당 주소를 통해 원본 변수에 접근하여 값을 변경할 수 있다.
예시
#include <stdio.h>
void Test(int *x) {
*x = 20; // 포인터를 통해 원본 변수의 값을 수정
}
int main() {
int a = 10;
Test(&a); // a의 주소를 전달
printf("%d\n", a); // 출력: 20
return 0;
}
📌 참조에 의한 전달( Call by reference )
참조에 의한 전달은 주소에 의한 전달과 비슷한 방식으로, 함수 호출 시 매개변수의 참조를 전달한다.
함수 호출 시 매개변수의 참조가 전달된다.
함수 내부에서 해당 참조를 통해 원본 객체나 데이터를 수정할 수 있다.
#include <iostream>
using namespace std;
void Test(int &x) {
x = 20; // 참조를 통해 원본 변수 값 수정
}
int main() {
int a = 10;
Test(a); // 참조를 전달
cout << a << endl; // 출력: 20
return 0;
}
앞선 글에서 쓰레드마다 Stack의 크기는 1MB로 제한되기 때문에 매개변수로 데이터를 전달할 때