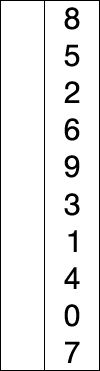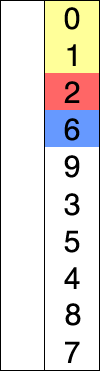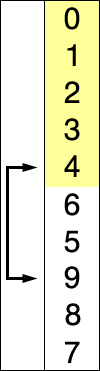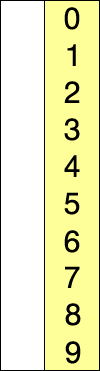
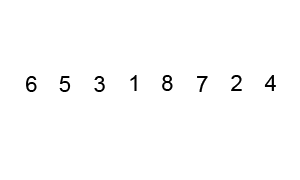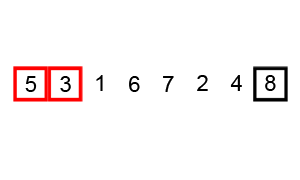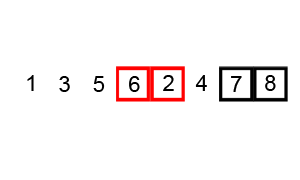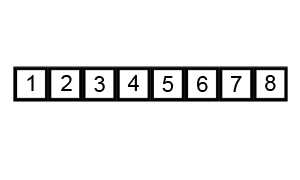루트 노드 또는 임의 노드에서 인접한 노드부터 먼저 탐색하는 방법
큐를 통해 구현한다. ( 해당 노드의 주변부터 탐색해야하기 때문 )
- 최소 비용 ( 즉, 모든 곳을 탐색하는 것보다 최소 비용이 우선일 때 )에 적합

시간 복잡도
- 인접 행렬 : O ( V^2 )
- 인접 리스트 : O ( V+E )
코드
#include <stdio.h>
int map[1001][1001], bfs[1001];
int queue[1001];
void init(int *, int size);
void BFS(int v, int N) {
int front = 0, rear = 0;
int pop;
printf("%d ", v);
queue[rear++] = v;
bfs[v] = 1;
while (front < rear) {
pop = queue[front++];
for (int i = 1; i <= N; i++) {
if (map[pop][i] == 1 && bfs[i] == 0) {
printf("%d ", i);
queue[rear++] = i;
bfs[i] = 1;
}
}
}
return;
}
int main(void) {
init(map, sizeof(map) / 4);
init(bfs, sizeof(bfs) / 4);
init(queue, sizeof(queue) / 4);
int N, M, V;
scanf("%d%d%d", &N, &M, &V);
for (int i = 0; i < M; i++)
{
int start, end;
scanf("%d%d", &start, &end);
map[start][end] = 1;
map[end][start] = 1;
}
BFS(V, N);
return 0;
}
void init(int *arr, int size) {
for (int i = 0; i < size; i++)
{
arr[i] = 0;
}
}'알고리즘' 카테고리의 다른 글
| [알고리즘] DFS (0) | 2024.11.11 |
|---|---|
| [알고리즘] 힙 정렬 ( Heap Sort ) (0) | 2024.11.10 |
| [알고리즘] 배열 ( Array ) (0) | 2024.09.17 |
| [알고리즘] 합병 정렬 (0) | 2024.08.28 |
| [알고리즘] 퀵 정렬 (0) | 2024.08.28 |