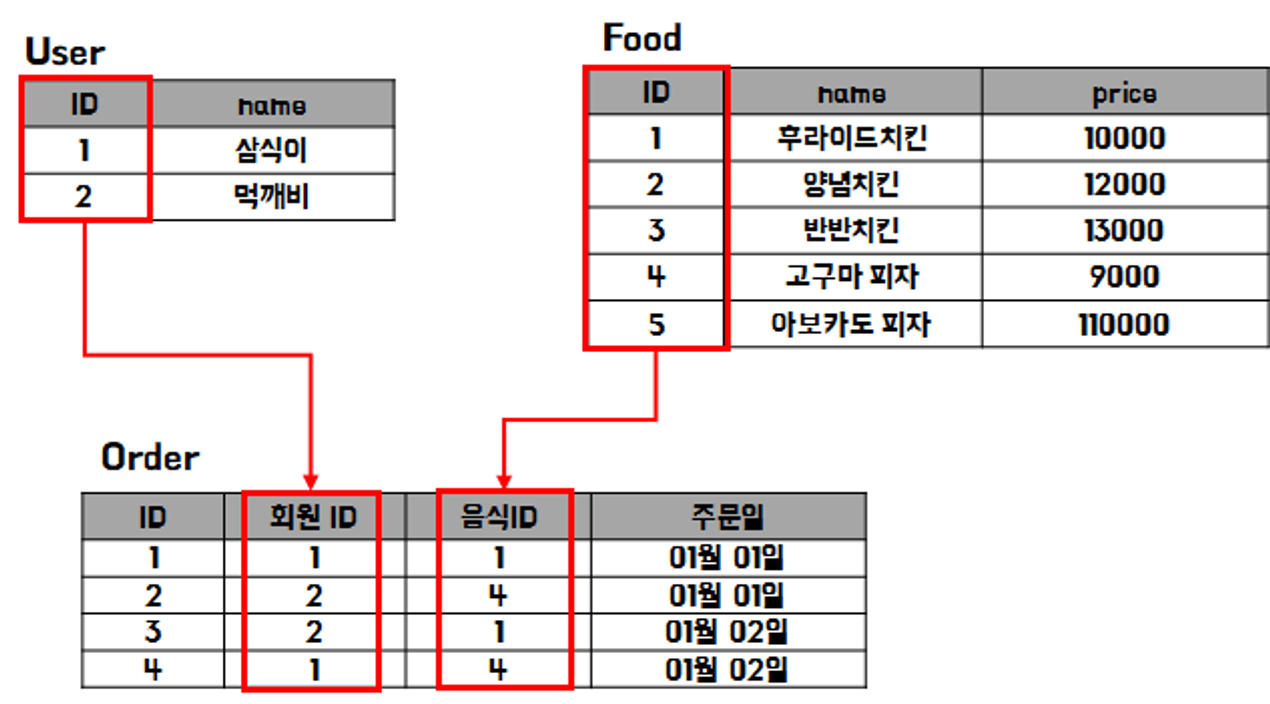
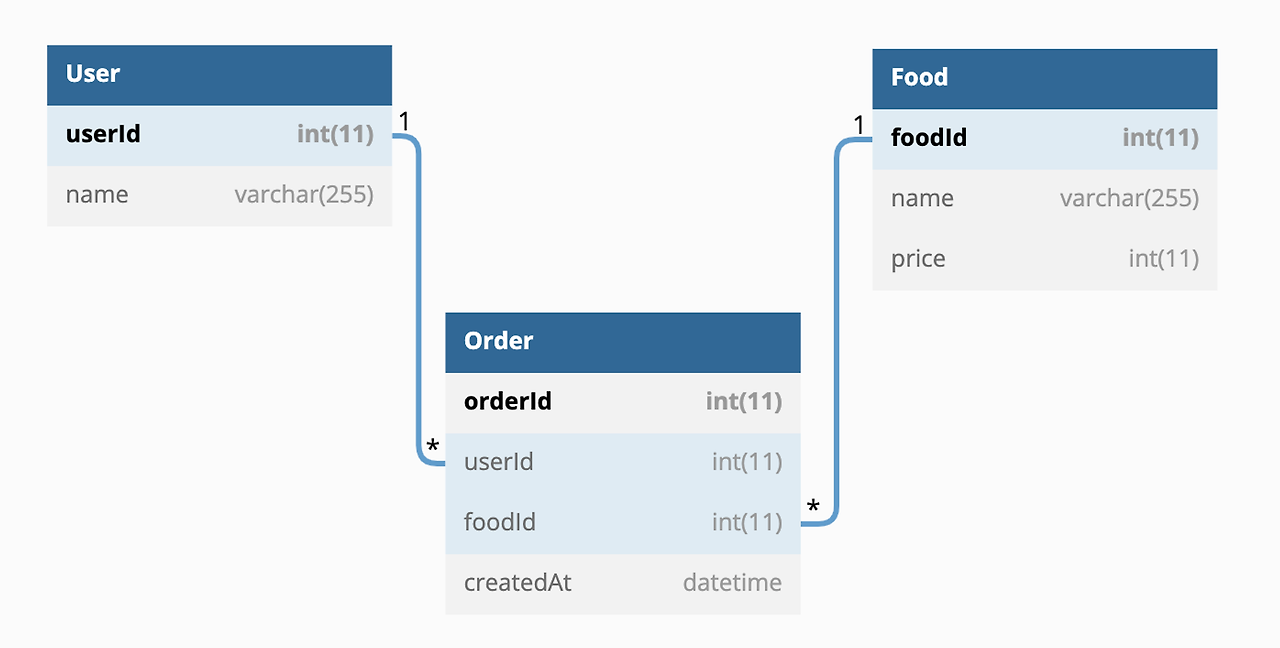
Prisma의 트랜잭션은 여러개의 쿼리를 하나의 트랜잭션으로 수행할 수 있는 Sequential 트랜잭션과 Prisma가 자체적으로 트랜잭션의 성공과 실패를 관리하는 Interactive 트랜잭션이 존재한다.
Sequential 트랜잭션
import { PrismaClient } from '@prisma/client';
const prisma = new PrismaClient();
// Sequential 트랜잭션은 순차적으로 실행된다
// 결과값은 각 쿼리의 순서대로 배열에 담겨 반환된다
const [posts, comments] = await prisma.$transaction([
prisma.posts.findMany(),
prisma.comments.findMany(),
]);
Sequential 트랜잭션은 Prisma의 여러 쿼리를 배열( [ ] )로 전달받아, 각 쿼리들을 순서대로 실행하는 특징이 있다.
이러한 특징은 여러 작업이 순차적으로 실행되어야할 때 사용할 수 있다.
import { PrismaClient } from '@prisma/client';
const prisma = new PrismaClient();
// Prisma의 Interactive 트랜잭션을 실행한다.
const result = await prisma.$transaction(async (tx) => {
// 트랜잭션 내에서 사용자를 생성한다.
const user = await tx.users.create({
data: {
email: 'testuser@gmail.com',
password: 'aaaa4321',
},
});
// 에러가 발생하여, 트랜잭션 내에서 실행된 모든 쿼리가 롤백된다.
throw new Error('트랜잭션 실패!');
return user;
});
또한, Sequential 트랜잭션은 Prisma의 모든 쿼리 메서드뿐만 아니라, Raw Query도 사용할 수 있다.
Interactive 트랜잭션
import { PrismaClient } from '@prisma/client';
const prisma = new PrismaClient();
// Prisma의 Interactive 트랜잭션을 실행합니다.
const result = await prisma.$transaction(async (tx) => {
// 트랜잭션 내에서 사용자를 생성합니다.
const user = await tx.users.create({
data: {
email: 'testuser@gmail.com',
password: 'aaaa4321',
},
});
// 에러가 발생하여, 트랜잭션 내에서 실행된 모든 쿼리가 롤백됩니다.
throw new Error('트랜잭션 실패!');
return user;
});- Interactive 트랜잭션은 모든 비즈니스 로직이 성공적으로 완료되거나 에러가 발생한 경우 Prisma 자체적으로 COMMIT 또는 ROLLBACK을 실행해 트랜잭션을 관리하는 장점을 가지고 있다.
- Interactive 트랜잭션은 트랜잭션 진행 중에도 비즈니스 로직을 처리할 수 있어, 복잡한 쿼리 시나리오를 효과적으로 구현할 수 있다.
- $transation() 메서드의 첫번째 인자 async(tx)는 우리가 일반적으로 사용하는 prisma 인스턴스와 같은 기능을 수행한다.
[게시판 프로젝트] 회원가입 API에 트랜잭션 적용하기
회원가입 API는 아래와 같은 비즈니스 로직을 가지고 있다.
- email, password, name, age, gender, profileImage를 body로 전달받는다.
- 동일한 email을 가진 사용자가 있는지 확인한다.
- Users 테이블에 email, password를 이용해 사용자를 생성한다.
- UserInfos 테이블에 name, age, gender, profileImage를 이용해 사용자 정보를 생성한다.
- 회원가입을 완료 처리한다.
여기서 3 사용자 및 4 사용자 정보를 생성하는 과정에서 에러가 발생하게 될 경우 문제가 생길 수 있다.
이를 해결하기 위해, 우리는 트랜잭션 ( Transaction )을 도입할 예정이다.
트랜잭션을 도입하면 여러 개의 쿼리를 하나의 작업으로 묶어, 하나의 쿼리가 실패할 경우 전체 트랜잭션을 취소 ( ROLLBACK ) 할 수 있어 데이터의 일관성을 유지할 수 있게 된다.
그렇다면, 트랜잭션을 도입해 회원가입 API를 리팩토링 해보자.
[게시판 프로젝트] 회원가입 트랜잭션 예시 코드
// src/routes/users.router.js
import { Prisma } from '@prisma/client';
/** 사용자 회원가입 API 트랜잭션 **/
router.post('/sign-up', async (req, res, next) => {
try {
const { email, password, name, age, gender, profileImage } = req.body;
const isExistUser = await prisma.users.findFirst({
where: {
email,
},
});
if (isExistUser) {
return res.status(409).json({ message: '이미 존재하는 이메일입니다.' });
}
// 사용자 비밀번호를 암호화합니다.
const hashedPassword = await bcrypt.hash(password, 10);
// MySQL과 연결된 Prisma 클라이언트를 통해 트랜잭션을 실행합니다.
const [user, userInfo] = await prisma.$transaction(
async (tx) => {
// 트랜잭션 내부에서 사용자를 생성합니다.
const user = await tx.users.create({
data: {
email,
password: hashedPassword, // 암호화된 비밀번호를 저장합니다.
},
});
// 트랜잭션 내부에서 사용자 정보를 생성합니다.
const userInfo = await tx.userInfos.create({
data: {
userId: user.userId, // 생성한 유저의 userId를 바탕으로 사용자 정보를 생성합니다.
name,
age,
gender: gender.toUpperCase(), // 성별을 대문자로 변환합니다.
profileImage,
},
});
// 콜백 함수의 리턴값으로 사용자와 사용자 정보를 반환합니다.
return [user, userInfo];
},
{
isolationLevel: Prisma.TransactionIsolationLevel.ReadCommitted,
},
);
return res.status(201).json({ message: '회원가입이 완료되었습니다.' });
} catch (err) {
next(err);
}
});
Prisma에서 격리 수준 설정
Prisma의 격리수준은 트랜잭션을 생성할 때, isolationLevel 옵션을 정의함으로써 설정할 수 있다.
import { Prisma } from '@prisma/client';
await prisma.$transaction(
async (tx) => { ... },
{
isolationLevel: Prisma.TransactionIsolationLevel.ReadCommitted,
},
);
격리 수준 ( Isolation Level )을 설정할 때, 현재 구현하려는 API에는 어떠한 격리 수준이 필요한지 명확하게 이해해야 한다. 이를 통해 효율적인 데이터베이스의 설계를 할 수 있고, 데이터의 일관성이 깨지지 않도록 구현할 수 있게 된다.
회원 가입 API는 결제시스템과 같이 높은 수준의 일관성을 요구하지 않기 때문에,
READ_COMMITED 격리 수준을 사용했다.
사용자 히스토리 ( UserHisotires ) 테이블 생성
이 테이블은 사용자의 정보가 변경될 때마다 변경 내역을 로깅 ( Logging )하기 위해 사용한다.
사용자 정보 변경 API를 구현하면서, 이 변경 내역을 사용자 히스토리 테이블에 함께 데이터를 생성하도록 구현해보자.
schma.prisma에 UserHistories model을 생성한다.
// schema.prisma
model Users {
userId Int @id @default(autoincrement()) @map("userId")
email String @unique @map("email")
password String @map("password")
createdAt DateTime @default(now()) @map("createdAt")
updatedAt DateTime @updatedAt @map("updatedAt")
userInfos UserInfos? // 사용자(Users) 테이블과 사용자 정보(UserInfos) 테이블이 1:1 관계를 맺습니다.
posts Posts[] // 사용자(Users) 테이블과 게시글(Posts) 테이블이 1:N 관계를 맺습니다.
comments Comments[] // 사용자(Users) 테이블과 댓글(Comments) 테이블이 1:N 관계를 맺습니다.
userHistories UserHistories[] // 사용자(Users) 테이블과 사용자 히스토리(UserHistories) 테이블이 1:N 관계를 맺습니다.
@@map("Users")
}
model UserHistories {
userHistoryId String @id @default(uuid()) @map("userHistoryId")
userId Int @map("userId") // 사용자(Users) 테이블을 참조하는 외래키
changedField String @map("changedField") // 변경된 필드명
oldValue String? @map("oldValue") // 변경 전 값
newValue String @map("newValue") // 변경 후 값
changedAt DateTime @default(now()) @map("changedAt")
// Users 테이블과 관계를 설정합니다.
user Users @relation(fields: [userId], references: [userId], onDelete: Cascade)
@@map("UserHistories")
}
Prisma db push 명령어를 이용해 동기화 한다.
# schema.prisma에 정의된 모델 정보를 DB와 동기화합니다.
npx prisma db push
UUID ( 범용 고유 식별자 )
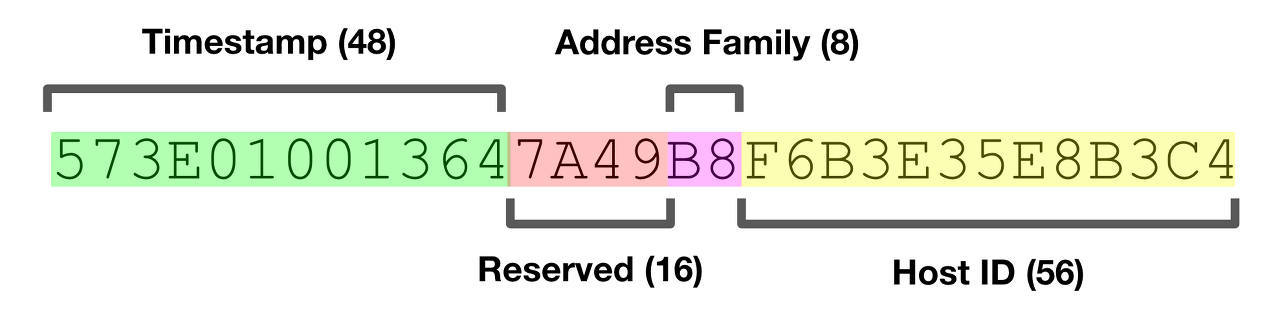
UUID ( Universally Unique Identifier, 범용 고유 식별자 )는 총 4개의 정보를 하이픈 ( - )으로 구분해 순차적으로 저장한 데이터 타입이다. 시간 정보를 포함하고 있어 생성된 순서대로 정렬이 되는 특징을 가지고 있다.
https://ko.wikipedia.org/wiki/%EB%B2%94%EC%9A%A9_%EA%B3%A0%EC%9C%A0_%EC%8B%9D%EB%B3%84%EC%9E%90
범용 고유 식별자 - 위키백과, 우리 모두의 백과사전
위키백과, 우리 모두의 백과사전. 범용 고유 식별자(汎用固有識別子, 영어: universally unique identifier, UUID)는 소프트웨어 구축에 쓰이는 식별자 표준으로, 개방 소프트웨어 재단(OSF)이 분산 컴퓨팅
ko.wikipedia.org
UUID 디코드 사용해보기
https://www.uuidtools.com/decode
UUID Decoder | UUIDTools.com
How to decode a UUID Embedded in every UUID is the version and variant of the UUID. Other information such as the time the UUID was generated can also be extracted in some cases. The tool above extracts this information automatically. The UUID version is r
www.uuidtools.com
사용자 히스토리 ( UserHistories ) 테이블은 사용자 정보에 대한 모든 변경 내역을 기록한다. 추후에 API 호출 히스토리와 같은 추가 정보를 기록하는 다른 히스토리 테이블을 만들면, 더욱 다양한 데이터를 수집할 수 있다.
사용자 히스토리 테이블은 일반적인 다른 테이블과는 조금 다르게 설계해야한다.
Integer 타입의 기본키나 createdAt, updatedAt과 같은 컬럼을 사용하기보다는 UUID를 사용해 컬럼 수를 최소화 하는 것이 로그 테이블에서 더욱 효율적인 설계가 된다.
[게시판 프로젝트] 사용자 정보 변경 API
[게시판 프로젝트] 사용자 정보 변경 API 비즈니스 로직
- 클라이언트가 로그인된 사용자인지 검증한다.
- 변경할 사용자 정보 name, age, gender, profileImage를 body로 전달받는다.
- 사용자 정보 ( UserInfoes ) 테이블에서 사용자의 정보들을 수정한다.
- 사용자의 변경된 정보 이력을 사용자 히스토리 ( UserHistories ) 테이블에 저장한다.
- 사용자 정보 변경 API를 완료한다.
사용자 정보 변경 API는 3번 사용자 정보의 수정과 4번 사용자 히스토리 데이터 삽입, 2개의 비즈니스 로직을 하나의 작업으로 처리해야한다.
비즈니스 로직을 수행하는 도중 오류가 발생할 경우, 데이터의 일관성이 깨지게 될 수 있다.
이렇게 되면, User History Table의 데이터들을 믿을 수 없게 되는 상황이 발생하게 된다.
[게시판 프로젝트] 사용자 정보 변경 API
// src/routes/users.router.js
/** 사용자 정보 변경 API **/
router.patch('/users/', authMiddleware, async (req, res, next) => {
try {
const { userId } = req.user;
const updatedData = req.body;
const userInfo = await prisma.userInfos.findFirst({
where: { userId: +userId },
});
await prisma.$transaction(
async (tx) => {
// 트랜잭션 내부에서 사용자 정보를 수정합니다.
await tx.userInfos.update({
data: {
...updatedData,
},
where: {
userId: userInfo.userId,
},
});
// 변경된 필드만 UseHistories 테이블에 저장합니다.
for (let key in updatedData) {
if (userInfo[key] !== updatedData[key]) {
await tx.userHistories.create({
data: {
userId: userInfo.userId,
changedField: key,
oldValue: String(userInfo[key]),
newValue: String(updatedData[key]),
},
});
}
}
},
{
isolationLevel: Prisma.TransactionIsolationLevel.ReadCommitted,
},
);
return res
.status(200)
.json({ message: '사용자 정보 변경에 성공하였습니다.' });
} catch (err) {
next(err);
}
});'데이터베이스' 카테고리의 다른 글
| [DATABASE] 트랜잭션 ( Transaction ) (1) | 2024.09.11 |
|---|---|
| [DATABASE] ORM과 Prisma (0) | 2024.09.06 |
| [DATABASE] Raw Query (0) | 2024.09.06 |
| [DATABASE] SELECT JOIN 연산자 (0) | 2024.09.05 |
| [DATABASE] SQL 제약조건 (0) | 2024.09.05 |